News
New survey paper on efficient methods for natural language processing published in TACL
Our new survey paper, “Efficient Methods for Natural Language Processing: A Survey,” was published in Transactions of the Association for Computational Linguistics (TACL). This paper surveys the landscape of efficient techniques in NLP. This paper was co-authored with a large team of colleagues from IST/U. of Lisbon and Instituto de Telecomunicações, Technical University of Darmstadt, Stony Brook University, Berliner Hochschule für Technik, University of Washington, University of Southern California, The Hebrew University of Jerusalem, University of Edinburgh, Cohere For AI, University of North Carolina at Chapel Hill, Unbabel, University of Bristol, IBM Research, Allen Institute for AI, Carnegie Mellon University, and IT University of Copenhagen.
Marcos Treviso, Ji-Ung Lee, Tianchu Ji, Betty van Aken, Qingqing Cao, Manuel R. Ciosici, Michael Hassid, Kenneth Heafield, Sara Hooker, Colin Raffel, Pedro H. Martins, André F. T. Martins, Jessica Zosa Forde, Peter Milder, Edwin Simpson, Noam Slonim, Jesse Dodge, Emma Strubell, Niranjan Balasubramanian, Leon Derczynski, Iryna Gurevych, Roy Schwartz; Efficient Methods for Natural Language Processing: A Survey. Transactions of the Association for Computational Linguistics 2023; 11 826–860. https://doi.org/10.1162/tacl_a_00577
You can read the paper here.
Abstract: Recent work in natural language processing (NLP) has yielded appealing results from scaling model parameters and training data; however, using only scale to improve performance means that resource consumption also grows. Such resources include data, time, storage, or energy, all of which are naturally limited and unevenly distributed. This motivates research into efficient methods that require fewer resources to achieve similar results. This survey synthesizes and relates current methods and findings in efficient NLP. We aim to provide both guidance for conducting NLP under limited resources, and point towards promising research directions for developing more efficient methods.
This entry was posted on July 12, 2023.
New paper on voltage scaled DNN accelerators published at GLSVLSI
Our new paper on applying voltage scaling to DNN accelerators has been published at the Great Lakes Symposium on VLSI (GLSVLSI ‘23).
This paper, “Precision and Performance-Aware Voltage Scaling in DNN Accelerators,” was co-authored with Stony Brook PhD alum Mallika Rathore and Professor Emre Salman.
You can read the paper here.
Abstract: A methodology is proposed to enhance the energy efficiency of systolic array based deep neural network (DNN) accelerators by enabling precision- and performance-aware voltage scaling. The proposed framework consists of three primary steps. In the first step, the voltage-dependent timing error probability for each output bit within the processing elements is analytically estimated. Next, these timing errors are injected into DNN models, helping us understand how inference accuracy is affected by lower operating voltages. In the last step, we apply error detection and correction to only select bits within the network, thereby improving inference accuracy while minimizing circuit overhead. For a 256X256 array operating at 0.7GHz and evaluating MobileNetV2 on ImageNet, we can reduce the nominal supply voltage from 0.9V to 0.5V with negligible (0.001%) latency overhead. This reduction in supply voltage reduces the inference energy by 79.4% while degrading inference accuracy by only 0.29%.
This entry was posted on June 05, 2023.
New paper on hardware acceleration of state machine replication published at NSDI
Our new paper on accelerating state machine replication with FPGA-based SmartNICs has been published at NSDI23.
This paper, “Waverunner: An Elegant Approach to Hardware Acceleration of State Machine Replication,” was co-authored with Stony Brook PhD students Mohammadreza Alimadadi and Hieu Mai, Stony Brook PhD alum Shenghsun Cho, and professors Michael Ferdman and Shuai Mu.
You can read the paper here or watch Reza’s presentation video here.
Abstract: State machine replication (SMR) is a core mechanism for building highly available and consistent systems. In this paper, we propose Waverunner, a new approach to accelerate SMR using FPGA-based SmartNICs. Our approach does not implement the entire SMR system in hardware; instead, it is a hybrid software/hardware system. We make the observation that, despite the complexity of SMR, the most common routine—the data replication—is actually simple. The complex parts (leader election, failure recovery, etc.) are rarely used in modern datacenters where failures are only occasional. These complex routines are not performance critical; their software implementations are fast enough and do not need acceleration. Therefore, our system uses FPGA assistance to accelerate data replication, and leaves the rest to the traditional software implementation of SMR.
Our Waverunner approach is beneficial in both the common and the rare case situations. In the common case, the system runs at the speed of the network, with a 99th percentile latency of 1.8 µs achieved without batching on minimum-size packets at network line rate (85.5 Gbps in our evaluation). In rare cases, to handle uncommon situations such as leader failure and failure recovery, the system uses traditional software to guarantee correctness, which is much easier to develop and maintain than hardware-based implementations. Overall, our experience confirms Waverunner as an effective and practical solution for hardware accelerated SMR—achieving most of the benefits of hardware acceleration with minimum added complexity and implementation effort.
This entry was posted on April 17, 2023.
Special Issue on Hardware Acceleration of Machine Learning
I have recently organized (with Michael Ferdman, Jorge Albericio, and Tushar Krisna) a special issue of IEEE Transactions on Computers focusing in hardware acceleration of machine learning, which has now been published. You can find our guest editorial, which provides a brief overview of the issue here.
This entry was posted on December 01, 2022.
New Paper on Producer Selection in Wireless Edge Environments Published at ICN
Our new paper on producer selection in wireless edge environments has been published at the ACM Conference on Information-Centric Networking (ICN). The paper, titled “OPSEL: optimal producer selection under data redundancy in wireless edge environments,” was co-authored with Stony Brook PhD student Mohammed Elbadry and Professor Fan Ye.
Abstract: In wireless edge environments, data redundancy among multiple neighboring nodes is common due to the need to support application performance, mitigate faults, or the intrinsic nature of applications (e.g., AR/VR, edge storage). Further, under data centric paradigms (e.g., Named Data Networking (NDN)), consumers that request the same data may leverage multicast so data are sent only once (e.g., VR games with data cached at multiple edge nodes). Naive strategies such as selecting a random neighbor or the prevailing wisdom of choosing the one with the strongest received signal strength (RSSI) cause more severe loss than other available producers. In this paper, we propose OPSEL, a single-hop dynamic producer(s) selection protocol that enables single and multiple consumers to continuously identify the optimal producer(s) (e.g., lowest loss) under constantly varying medium conditions. When Data is available single-hop, OPSEL’s goal is to have the minimum number of producers sending to all consumers and meeting their performance needs without explicit coordination messages. Experiments on a real prototype show that OPSEL is 3% away in loss rate and has the same latency as the theoretical ideal, while naive timer methods can incur up to 60% more loss and 2-3× latency.
This entry was posted on September 06, 2022.
New paper on sparsity and quantization of attention in transformer networks
Our new paper, led by PhD student Tianchu Ji, will be published in Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021. The work will also be presented in the Repl4NLP workshop.
Tianchu Ji, Shraddhan Jain, Michael Ferdman, Peter Milder, H. Andrew Schwartz, and Niranjan Balasubramanian. “On the Distribution, Sparsity, and Inference-time Quantization of Attention Values in Transformers.” Accepted to appear in Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021.
You can read the paper on arXiv, and you can find our data and code on GitHub.
Here is Tianchu’s three-minute overview video:
Abstract: How much information do NLP tasks really need from a transformer’s attention mechanism at application-time (inference)? From recent work, we know that there is sparsity in transformers and that the floating-points within its computation can be discretized to fewer values with minimal loss to task accuracies. However, this requires retraining or even creating entirely new models, both of which can be expensive and carbon-emitting. Focused on optimizations that do not require training, we systematically study the full range of typical attention values necessary. This informs the design of an inference-time quantization technique using both pruning and logscaled mapping which produces only a few (e.g. 23) unique values. Over the tasks of question answering and sentiment analysis, we find nearly 80% of attention values can be pruned to zeros with minimal (< 1.0%) relative loss in accuracy. We use this pruning technique in conjunction with quantizing the attention values to only a 3-bit format, without retraining, resulting in only a 0.8% accuracy reduction on question answering with fine-tuned RoBERTa.
This entry was posted on June 25, 2021.
New paper on FPGA model checking to appear in ACM TRETS
Our new paper has been accepted to appear in ACM Transactions on Reconfigurable Technology and Systems (TRETS), in a special issue dedicated to FPL 2019. The paper is available here.
Shenghsun Cho, Mrunal Patel, Michael Ferdman, and Peter Milder. “Practical Model Checking on FPGAs.” ACM Transactions on Reconfigurable Technology and Systems, Volume 14, Issue 2, July 2021.
This paper is an extension of our FPL2019 paper.
Abstract: Software verification is an important stage of the software development process, particularly for mission-critical systems. As the traditional methodology of using unit tests falls short of verifying complex software, developers are increasingly relying on formal verification methods, such as explicit state model checking, to automatically verify that the software functions properly. However, due to the ever-increasing complexity of software designs, model checking cannot be performed in a reasonable amount of time when running on general-purpose cores, leading to the exploration of hardware-accelerated model checking. FPGAs have been demonstrated to be promising verification accelerators, exhibiting nearly three orders of magnitude speed-up over software. Unfortunately, the “FPGA programmability wall,” particularly the long synthesis and place-and-route times, block the general adoption of FPGAs for model checking.
To address this problem, we designed a runtime-programmable pipeline specifically for model checkers on FPGAs to minimize the “preparation time” before a model can be checked. Our design of the successor state generator and the state validator modules enables FPGA-acceleration of model checking without incurring the time-consuming FPGA implementation stages, reducing the preparation time before checking a model from hours to less than a minute, while incurring only a 26% execution time overhead compared to model-specific implementations.
This entry was posted on February 01, 2021.
New paper on WiFi medium analysis on the edge to appear at ICC
Our new paper has been accepted to appear at the IEEE International Conference on Communications (ICC ‘21). This paper, “Aletheia: A Lightweight Tool for Wi-Fi Medium Analysis on the Edge,” was co-authored with Stony Brook PhD student Mohammed Elbadry and Professor Fan Ye.
Abstract: With the plethora of wireless devices in limited spaces running multiple WiFi standards (802.11 a/b/g/n/ac), gaining an understanding of network latency, loss, and medium utilization becomes extremely challenging. Microsecond timing fidelity with protocols is critical to network performance evaluation and design; such fine-grained timing offers insights that simulations cannot deliver (e.g., precise timing through hardware and software implementations). However, currently there is no suitable efficient, lightweight tool for such purposes. This paper introduces Aletheia, an open-source tool that enables users to select their interested attributes in WiFi frames, quantify and visualize microsecond granularity medium utilization using low-cost commodity edge devices for easy deployment. Aletheia uses selective attribute extraction to filter frame fields; it reduces data storage and CPU overhead by 1 and 2 orders of magnitude, respectively, compared to existing tools (e.g., Wireshark, tshark). It provides flexible tagging and visualization features to examine the medium and perform different analysis to understand protocol behavior under different environments. We use Aletheia to capture and analyze 120M frames in 24 hours at 4 locations to demonstrate its value in production and research network performance evaluation and troubleshooting. We find that WiFi management beacons can consume medium heavily (up to 40%); the common practice of categorizing networks based on environment types (e.g., office vs. home) is problematic, calling for a different evaluation methodology and new designs.
This entry was posted on January 27, 2021.
New paper on data-centric multicast communications to appear at Symposium on Edge Computing
Our new paper has been accepted to appear at the ACM/IEEE Symposium on Edge Computing (SEC ‘20). This paper, “Pub/Sub in the Air: A Novel Data-centric Radio Supporting Robust Multicast in Edge Environments,” was co-authored with Stony Brook PhD student Mohammed Elbadry and Professors Fan Ye and Yuanyuan Yang.
Abstract: Peer communication among edge devices (e.g., mobiles, vehicles, IoT and drones) is frequently data-centric: most important is obtaining data of desired content from suitable nodes; who generated or transmitted the data matters much less. Typical cases are robust one-to-many data sharing: e.g., a vehicle sending weather, road, position and speed data streams to nearby cars continuously. Unfortunately, existing address-based wireless communication is ill-suited for such purposes.
We propose V-MAC, a novel data-centric radio that provides a pub/sub abstraction to replace the point-to-point abstraction in existing radios. It filters frames by data names instead of MAC addresses, thus eliminating complexities and latencies in neighbor discovery and group maintenance in existing radios. V-MAC supports robust, scalable and high rate multicast with consistently low losses across receivers of varying reception qualities. Experiments using a Raspberry Pi and commodity WiFi dongle based prototype show that V-MAC reduces loss rate from WiFi broadcast’s 50–90% to 1–3% for up to 15 stationary receivers, 4–5 moving people, and miniature and real vehicles. It cuts down filtering latency from 20us in WiFi to 10us for up to 2 million data names, and improves cross stack latency 60–100× for TX/RX paths. We have ported V-MAC to 4 major WiFi chipsets (including 802.11 a/b/g/n/ac radios), 6 different platforms (Android, embedded and FPGA systems), 7 Linux kernel versions, and validated up to 900Mbps multicast data rate and interoperation with regular WiFi. We will release V-MAC as a mature, reusable asset for edge computing research.
This entry was posted on August 07, 2020.
NSF Funds work on Accelerators for Sparse Transformers
The National Science Foundation has provided new funding for our work on exploiting sparsity in transformers. This is a joint project combining computer architecture and machine learning, with Niranjan Balasubramanian, Mike Ferdman, and Andrew Schwartz.
This entry was posted on August 06, 2020.
New paper on modeling error probability of voltage-scaled circuits to appear in TVLSI
A new paper from our group has been accepted to appear in IEEE Transactions on VLSI. This new work, motivated by the need for energy efficient machine learning, studies the relationship between voltage scaling, clock frequency, and error probability of multiply-accumulate units. The paper is available here.
This paper, “Error Probability Models for Voltage-Scaled Multiply-Accumulate Units,” was co-authored with PhD student Mallika Rathore and Professor Emre Salman.
Abstract: Energy efficiency is a critical design objective in deep learning hardware, particularly for real-time machine learning applications where the processing takes place on resource-constrained platforms. The inherent resilience of these applications to error makes voltage scaling an attractive method to enhance efficiency. Timing error probability models are proposed in this article to better understand the effects of voltage scaling on error rates and power consumption of multiply-accumulate units. The accuracy of the proposed models is demonstrated via Monte Carlo simulations. These models are then used to quantify the related tradeoffs without relying on time-consuming hardware-level simulations. Both modern FinFET and emerging tunneling field-effect transistor (TFET) technologies are considered to explore the dependence of the effects of voltage scaling on these two technologies.
This entry was posted on April 06, 2020.
New paper on heterogeneous-ISA multi-cores to appear at ISCA 2020
Our new paper, which proposes a lightweight method for migrating threads in heterogeneous-ISA multi-core systems, has been accepted to appear at ISCA 2020.
This paper, “Flick: Fast and Lightweight ISA-Crossing Call for Heterogeneous-ISA Environments,” was co-authored with Stony Brook PhD students Shenghsun Cho, Han Chen and Sergey Madaminov and Prof. Mike Ferdman.
Abstract: Heterogeneous-ISA multi-core systems have performance and power consumption benefits. Today, numerous system components, such as NVRAMs and Smart NICs, already have built-in general purpose cores with ISAs different from that of the host CPUs, effectively making many modern systems heterogeneous-ISA multi-core systems. However, programming and utilizing such systems efficiently is difficult and requires extensive support from the host operating systems. Existing programming solutions are complex, requiring dramatic changes to the systems, often incurring significant performance overheads.
To address this problem, we propose Flick: Fast and Lightweight ISA-Crossing Call, for migrating threads in heterogeneous-ISA multi-core systems. By leveraging hardware virtual memory support and standard operating system mechanisms, a software thread can transparently migrate between cores with different ISAs. We prototype a heterogeneous-ISA multi-core system using FPGAs with off-the-shelf hardware and software to evaluate Flick. Experiments with microbenchmarks and near-data-processing workloads show that Flick requires only minor changes to the existing OS and software, and incurs only 18microsecond round trip overhead for migrating a thread through PCIe, which is at least 23x lower than prior works.
The paper is available on IEEE Xplore.
This entry was posted on March 04, 2020.
New paper on sorting large data sets with FPGAs to appear at FPGA 2020
Our new paper on using FPGAs to greatly accelerate sorting of large sets of data has been accepeted to appear at FPGA 2020.
This paper, “FPGA-Accelerated Samplesort for Large Data Sets,” was co-authored with Stony Brook PhD students Han Chen and Sergey Madaminov and Prof. Mike Ferdman.
Abstract: Sorting is a fundamental operation in many applications such as databases, search, and social networks. Although FPGAs have been shown very effective at sorting data sizes that fit on chip, systems that sort larger data sets by shuffling data on and off chip are bottlenecked by costly merge operations or data transfer time.
We propose a new technique for sorting large data sets, which uses a variant of the samplesort algorithm on a server with a PCIe-connected FPGA. Samplesort avoids merging by randomly sampling values to determine how to partition data into non-overlapping buckets that can be independently sorted. The key to our design is a novel parallel multi-stage hardware partitioner, which is a scalable high-throughput solution that greatly accelerates the samplesort partitioning step. Using samplesort for FPGA-accelerated sorting provides several advantages over mergesort, while also presenting a number of new challenges that we address with cooperation between the FPGA and the software running on the host CPU.
We prototype our design using Amazon Web Services FPGA instances, which pair a Xilinx Virtex UltraScale+ FPGA with a high-performance server. Our experiments demonstrate that our prototype system sorts 230 key-value records with a speed of 7.2 GB/s, limited only by the on-board DRAM capacity and available PCIe bandwidth. When sorting 230 records, our system exhibits a 37.4x speedup over the widely used GNU parallel sort on an 8-thread state-of-the-art CPU.
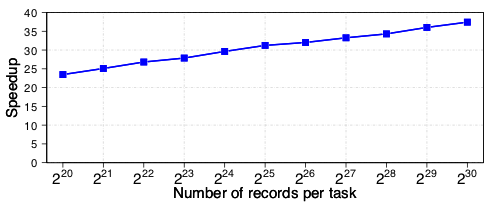 This graph illustrates the speedup of our implementation relative to parallel GNU Sort (8 threads). Please see paper for more detail.
This graph illustrates the speedup of our implementation relative to parallel GNU Sort (8 threads). Please see paper for more detail.
This entry was posted on November 22, 2019.
New overview paper on Argus to appear in IEEE Micro Special Issue
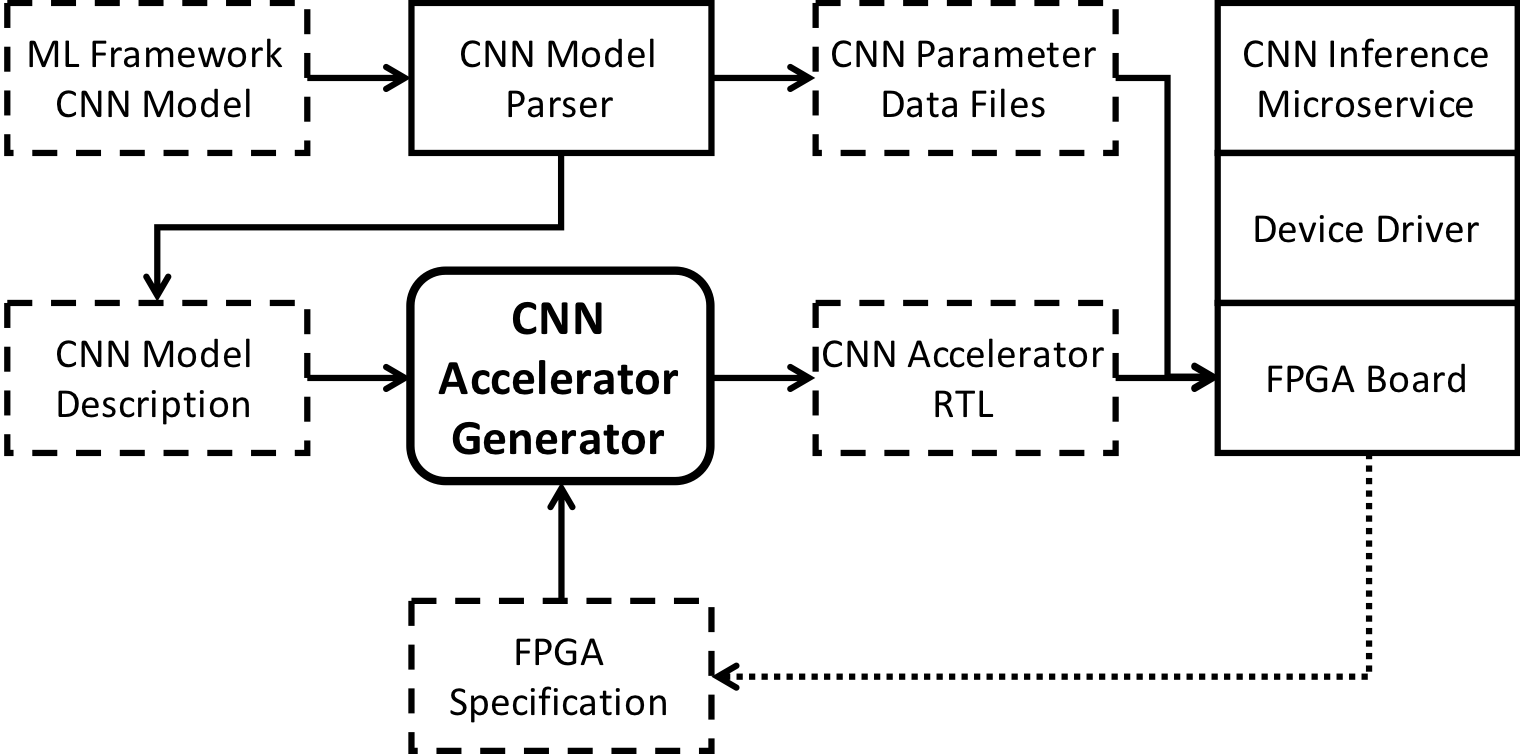
A new overview paper on Argus, our framework and generator for accelerating CNNs on FPGAs, has been accepted to appear in IEEE Micro, in a special issue on Machine Learning Acceleration.
This paper, “Argus: an End-to-End Framework for Accelerating CNNs on FPGAs,” was co-authored with PhD students Yongming Shen and Tianchu Ji and my collaborator Prof. Mike Ferdman.
Abstract: Advances in deep learning have led to the widespread use of convolutional neural networks (CNNs) for solving the most challenging computer vision problems. However, the high computational intensity of CNNs is beyond the capability of general-purpose CPUs, requiring specialized hardware acceleration. In particular, FPGAs have been shown effective for CNNs. Unfortunately, the difficulty of manually implementing CNN accelerators for FPGAs limits their adoption.
We present Argus, an end-to-end framework for accelerating CNNs on FPGAs. The core of Argus is an accelerator generator that translates high-level CNN descriptions into efficient multi-core accelerator designs. Argus explores an extensive design space, jointly optimizing all aspects of the design for the target FPGA and generating multi-core accelerator designs that achieve near-perfect dynamic arithmetic unit utilization. To minimize user effort, Argus includes a model parser for importing CNN models from popular machine learning frameworks, and a software stack for running an FPGA-backed CNN inference microservice.
This entry was posted on July 12, 2019.
New paper on Programmable Model Checking Hardware to Appear at FPL 2019
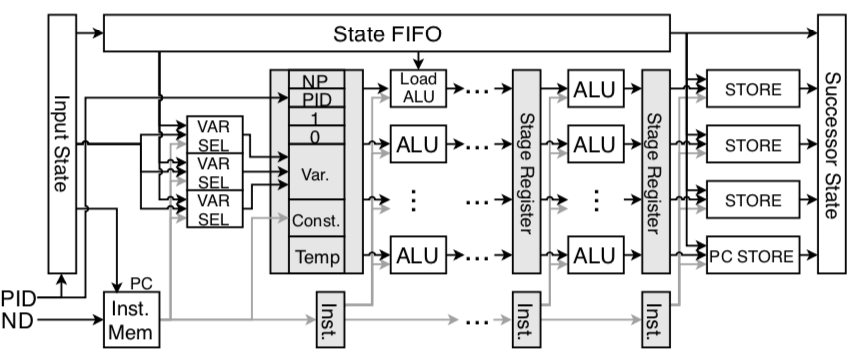
A new paper describing our recent work on programmable pipelines for accelerating model checking hardware has been accepted to appear at the International Conference on Field-Programmable Logic and Applications (FPL 2019).
This paper, titled “Runtime Programmable Pipelines for Model Checkers on FPGAs,” was co-authored with PhD students Mrunal Patel and Shenghsun Cho and my collaborator Prof. Mike Ferdman. The paper is available on IEEE Xplore.
Abstract: Software verification is an important stage of the software development process, particularly for mission-critical systems. As the traditional methodology of using unit tests falls short of verifying complex software, developers are increasingly relying on formal verification methods, such as explicit state model checking, to automatically verify that the software functions properly. However, due to the ever-increasing complexity of software designs, model checking software running on general purpose cores cannot be performed in a reasonable amount of time, leading to the exploration of hardware-accelerated model checking. FPGAs have been demon- strated as a promising accelerator because of their high throughput, inherent parallelism, and flexibility. Unfortunately, the “FPGA programmability wall,” particularly the long synthesis and place-and- route times, block the general adoption of FPGAs for model checking.
To address this problem, we designed a runtime-programmable pipeline specifically for model checkers on FPGAs to minimize the “preparation time” before a model can be checked. Our runtime- programmable pipeline design of the successor state generator and the state validator modules enables FPGA acceleration of model checking without incurring the time-consuming FPGA implementation stages. Our experimental results show that the runtime-programmable pipeline reduces the preparation time before checking a new or modified model from multiple hours to less than a minute, while maintaining similar throughput as FPGA model checkers with model-specific pipelines.
This entry was posted on May 17, 2019.
Poster on Sorting Hardware at FCCM
Han Chen will be presenting a poster at FCCM 2019 on our recent work on accelerating the sorting of large sets of data using FPGAs.
Han Chen, Sergey Madaminov, Michael Ferdman and Peter Milder. “Soring Large Data Sets with FPGA-Accelerated Samplesort.” Poster, FCCM 2019.
Han will be presenting during poster session 3 on Tuesday 4/30/19.
This entry was posted on April 27, 2019.
New Graduate Course on Deep Learning Hardware
This spring, I will be teaching my new graduate course: ESE 587 Hardware Architectures for Deep Learning. The course focuses on the design and implementation of specialized digital hardware systems for deep learning algorithms. The course will include hands-on FPGA experience with Xilinx Zynq.
A syllabus for the course is available here.
This entry was posted on November 04, 2018.
Poster Presentation at MobiCom 2018
Mohammed Elbadry will be presenting a poster at MobiCom 2018 on our recent work on data-centric vehicular networking.
Mohammed Elbadry, Bing Zhou, Fan Ye, Peter Milder, and YuanYuan Yang. “Poster: A Raspberry Pi Based Data-Centric MAC for Robust Multicast in Vehicular Network.” MobiCom 2018.
You can read the poster’s abstract here.
This entry was posted on October 26, 2018.
New work on using FPGAs to accelerate homomorphic encryption to appear
Our recent work in collaboration with a team from CEA (The French Alternative Energies and Atomic Energy Commission) LIST institute has been accepted to appear at the Conference on Cryptographic Hardware and Embedded Systems 2018.
The paper, “Data Flow Oriented Hardware Design of RNS-based Polynomial Multiplication for SHE Acceleration” was authored by Joël Cathébras, Alexandre Carbon, Peter Milder, Renaud Sirdey, and Nicolas Ventroux. In this work, we use an FPGA to residue polynomial multiplication. To do so, we adapted Spiral to generate efficient hardware implementations of the Number Theoretic Transform (NTT), and added a new hardware structure that changes its twiddle factors on the fly.
Please check back soon for a pre-print.
This entry was posted on July 06, 2018.
New paper on FPGA-based model checking to appear at FPL2018
A new paper on using FPGAs for swarm-based model checking, co-authored with Shenghsun Cho and Mike Ferdman, will appear at FPL 2018.
The paper is available on IEEE Xplore.
Abstract—Explicit state model checking has been widely used to discover difficult-to-find errors in critical software and hard- ware systems by exploring all possible combinations of control paths to determine if any input sequence can cause the system to enter an illegal state. Unfortunately, the vast state spaces of modern systems limit the ability of current general-purpose CPUs to perform explicit state model checking effectively due to the computational complexity of the model checking process. Complex software may require days or weeks to go through the formal verification phase, making it impractical to use model checking as part of the regular software development process.
In this work, we explore the possibility of leveraging FPGAs to overcome the performance challenges of model checking. We designed FPGASwarm, an FPGA model checker based on the concept of Swarm verification. FPGASwarm provides the necessary parallelism, performance, and flexibility to achieve high-throughput and reconfigurable explicit state model check- ing. Our experimental results show that, using a Xilinx Virtex- 7 FPGA, the FPGASwarm can achieve near three orders of magnitude speedup over the conventional software approach to state exploration.
Citation: Shenghsun Cho, Michael Ferdman, and Peter Milder. “FPGASwarm: High Throughput Model Checking on FPGAs.” To appear at the 28th International Conference on Field Programmable Logic and Applications (FPL), 2018.
This entry was posted on May 22, 2018.
New paper on Scalable Memory Interconnects for DNN Accelerators to appear at FPL 2018
A new paper, co-authored with Yongming Shen, Tianchu Ji, and Mike Ferdman has been accepted to appear at FPL2018.
The paper is available on IEEE Xplore, and an extended version is available on arXiv.
Abstract—To cope with the increasing demand and computational intensity of deep neural networks (DNNs), industry and academia have turned to accelerator technologies. In particular, FPGAs have been shown to provide a good balance between performance and energy efficiency for accelerating DNNs. While significant research has focused on how to build efficient layer processors, the computational building blocks of DNN accelerators, relatively little attention has been paid to the on-chip interconnects that sit between the layer processors and the FPGA’s DRAM controller.
We observe a disparity between DNN accelerator interfaces, which tend to comprise many narrow ports, and FPGA DRAM controller interfaces, which tend to be wide buses. This mismatch causes traditional interconnects to consume significant FPGA resources. To address this problem, we designed Medusa: an optimized FPGA memory interconnect which transposes data in the interconnect fabric, tailoring the interconnect to the needs of DNN layer processors. Compared to a traditional FPGA interconnect, our design can reduce LUT and FF use by 4.7x and 6.0x, and improves frequency by 1.8x.
Citation: Yongming Shen, Tianchu Ji, Michael Ferdman, and Peter Milder. “Medusa: A Scalable Memory Interconnect for Many-Port DNN Accelerators and Wide DRAM Controller Interfaces.” To appear at the 28th International Conference on Field Programmable Logic and Applications (FPL), 2018.
This entry was posted on May 22, 2018.
New paper on VM-HDL co-simulation framework to appear at FPGA18
Our new paper, which describes our recent work on creating a framework that allows co-simulation of server systems with PCIe-connected FPGAs, has been accepted to appear at FPGA 2018. We are also planning an open source release of this framework.
“A Full-System VM-HDL Co-Simulation Framework for Servers with PCIe-Connected FPGAs.” Shenghsun Cho, Mrunal Patel, Han Chen, Peter Milder, and Michael Ferdman. To appear at FPGA 2018.
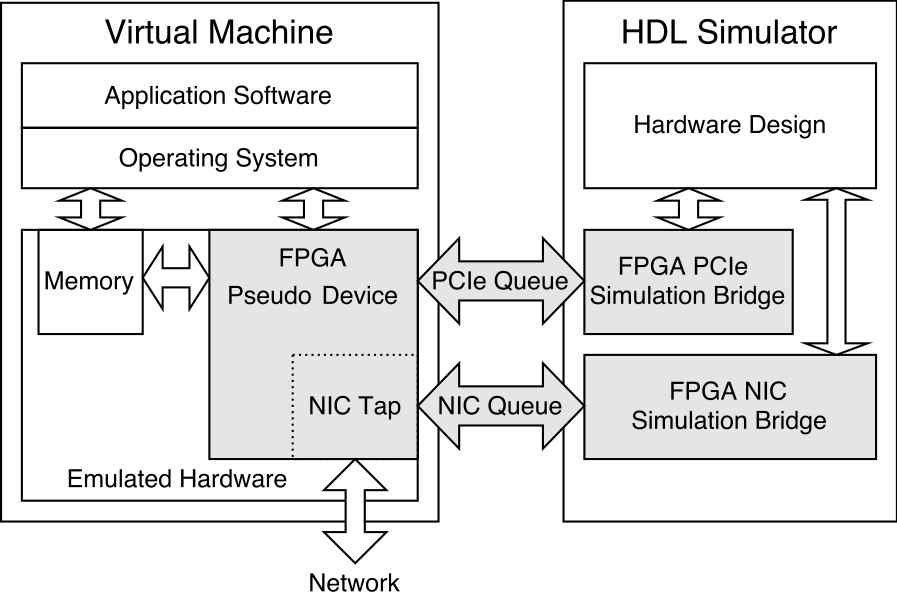
Abstract: The need for high-performance and low-power acceleration technologies in servers is driving the adoption of PCIe-connected FPGAs in datacenter environments. However, the co-development of the application software, driver, and hardware HDL for server FPGA platforms remains one of the fundamental challenges standing in the way of wide-scale adoption. The FPGA accelerator development process is plagued by a lack of comprehensive full-system simulation tools, unacceptably slow debug iteration times, and limited visibility into the software and hardware at the time of failure.
In this work, we develop a framework that pairs a virtual machine and an HDL simulator to enable full-system co-simulation of a server system with a PCIe-connected FPGA. Our framework enables rapid development and debugging of unmodi ed application software, operating system, device drivers, and hardware design.
Once the system is debugged, neither the software nor the hardware requires any changes before being deployed in a production environment. In our case studies, we nd that the co-simulation framework greatly improves debug iteration time while providing invaluable visibility into both the software and hardware components.
The paper is available on the ACM Digital Library.
This entry was posted on December 01, 2017.
NSF funds work on hardware and software for edge computing
The National Science Foundation has funded our work that aims to create a flexible hardware and software framework for next generation edge computing devices.
Please read more in this article at the Stony Brook College of Engineering and Applied Sciences website.
This entry was posted on July 02, 2017.
New paper on CNN accelerator architectures to appear at ISCA 2017
Our new paper on improving the efficiency of hardware accelerators for convolutional neural networks has been accepted for publication at the 44th International Symposium on Computer Architecture (ISCA), 2017.
This paper, co-authored with Yongming Shen (Stony Brook CS PhD student) and Stony Brook CS professor Mike Ferdman, proposes a new Convolutional Neural Network (CNN) accelerator paradigm and an accompanying automated design methodology that partitions the available FPGA resources into multiple processors, each of which is tailored for a different subset of the CNN convolutional layers.
Yongming Shen, Michael Ferdman, and Peter Milder. “Maximizing CNN Accelerator Efficiency Through Resource Partitioning.” To appear at The 44th International Symposium on Computer Architecture (ISCA), 2017.
The paper is available on IEEE Xplore.
This entry was posted on March 08, 2017.
New Paper on Bandwidth-Efficient CNN accelerators to appear at FCCM 2017
Our new paper on bandwidth-efficient hardware accelerators for convolutional neural networks will appear at FCCM 2017. This paper, co-authored with Stony Brook CS PhD student Yongming Shen and Stony Brook CS professor Mike Ferdman, proposes a new method to efficiently balance between the transfer costs of CNN data and CNN parameters and describes a new flexible architecture that is able to reduce the overall communication requirement.
Abstract—Convolutional neural networks (CNNs) are used to solve many challenging machine learning problems. Interest in CNNs has led to the design of CNN accelerators to improve CNN evaluation throughput and efficiency. Importantly, the bandwidth demand from weight data transfer for modern large CNNs causes CNN accelerators to be severely bandwidth bottlenecked, prompting the need for processing images in batches to increase weight reuse. However, existing CNN accelerator designs limit the choice of batch sizes and lack support for batch processing of convolutional layers.
We observe that, for a given storage budget, choosing the best batch size requires balancing the input and weight transfer. We propose Escher, a CNN accelerator with a flexible data buffering scheme that ensures a balance between the input and weight transfer bandwidth, significantly reducing overall bandwidth requirements. For example, compared to the state-of-the-art CNN accelerator designs targeting a Virtex-7 690T FPGA, Escher reduces the accelerator peak bandwidth requirements by 2.4× across both fully-connected and convolutional layers on fixed-point AlexNet, and reduces convolutional layer bandwidth by up to 10.5× on fixed-point GoogleNet.
Yongming Shen, Michael Ferdman, and Peter Milder. “Escher: A CNN Accelerator with Flexible Buffering to Minimize Off-Chip Transfer.” To appear at The 25th IEEE International Symposium on Field-Programmable Custom Computing Machines (FCCM), 2017.
The paper is available on IEEE Xplore.
This entry was posted on March 06, 2017.
New article on hardware reliability to appear in ACM TECS
A new article focusing on hardware implementation of execution stream compression will appear in ACM Transactions on Embedded Computing Systems, in a special issue on Secure and Fault-tolerant Embedded Computing. This paper was co-authored with Maria Isabel Mera (a Stony Brook ECE MS alum, currently a PhD student at NYU), Jonah Caplan and Seyyed Hasan Mozafari (graduate students at McGill University), and Prof. Brett Meyer from McGill. This work was based in part on Maria Isabel Mera’s MS thesis.
“Area, Throughput and Power Trade-offs for FPGA- and ASIC-based Execution Stream Compression.” Maria Isabel Mera, Jonah Caplan, Seyyed Hasan Mozafari, Brett H. Meyer, and Peter Milder. To appear in ACM Trans. on Embedded Computing Systems, 2017.
Abstract: An emerging trend in safety-critical computer system design is the use of compression, e.g., using cyclic redundancy check (CRC) or Fletcher Checksum (FC), to reduce the state that must be compared to verify correct redundant execution. We examine the costs and performance of CRC and FC as compression algorithms when implemented in hardware for embedded safety-critical systems. To do so, we have developed parameterizable hardware generation tools targeting CRC and two novel FC implementations. We evaluate the resulting designs implemented for FPGA and ASIC and analyze their efficiency; while CRC is often best, FC dominates when high throughput is needed.
Please check back later for a pre-print.
This entry was posted on February 14, 2017.
New paper to appear at ICASSP in special session on signal processing education
A new paper, entitled “Practical Matlab Experience in Lecture-Based Signals and Systems Courses,” which I co-authored with Prof. Mónica Bugallo, will appear at the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), in the special session on Advances in Signal Processing Education.
This entry was posted on January 09, 2017.
Poster on neural network hardware to appear at FPGA 2017
Yongming Shen will be presenting a poster on our current work to implement bandwidth-efficienct fully-connect neural network layers next month.
Yongming Shen, Michael Ferdman, and Peter Milder. “Storage-Efficient Batching for Minimizing Bandwidth of Fully-Connected Neural Network Layers.” Poster to appear at FPGA 2017.
This entry was posted on January 08, 2017.
NSF Funds our work on efficient spectrum sensing
The National Science Foundation’s Enhancing Access to the Radio Spectrum program has funded our group’s work on efficient distributed spectrum sensing. The goal of this work is to enable crowd-sourced collaborative spectrum sensing including low-cost low-power FPGA-based hardware and novel interpolation and optimization techniques to aggregate and analyze data.
This work is a collaboration with Samir Das and Himanshu Gupta (Stony Brook CS), and Petar Djurić (Stony Brook ECE).
You can read more at the NSF website.
This entry was posted on September 19, 2016.
Announcing the 2016 MEMOCODE design contest
I am organizing the 2016 MEMOCODE Design Contest, which begins today and lasts through September 13.
This year’s contest problem is will be k-means clustering. You can read the contest description here, and read more about MEMOCODE 2016 here.
This entry was posted on August 15, 2016.
“Fused Layer CNN Accelerators” to appear at MICRO 2016
Our new paper “Fused Layer CNN Accelerators” by Manoj Alwani, Han Chen, Michael Ferdman, and Peter Milder has been accepted to appear at MICRO 2016.
The paper is available on IEEE Xplore.
In this work, we observe that a previously unexplored dimension exists in the design space of CNN accelerators that focuses on the dataflow across convolutional layers. We find that we are able to fuse the processing of multiple CNN layers by modifying the order in which the input data are brought on chip, enabling caching of intermediate data between the evaluation of adjacent CNN layers. We demonstrate the effectiveness of our approach by constructing a fused-layer CNN accelerator for the first five convolutional layers of the VGGNet-E network, and find that, by using 362KB of on-chip storage, our fused-layer accelerator minimizes off-chip feature map data transfer, reducing the total transfer by 95%, from 77MB down to 3.6MB per image.
This entry was posted on June 28, 2016.
New paper on CNN accelerator efficiency to appear at FPL 2016
Our recent paper on CNN accelerator hardware: “Overcoming Resource Underutilization in Spatial CNN Accelerators” has been accepted to appear at the International Conference on Field-Programmable Logic and Applications (FPL) 2016. This paper was co-written with Yongming Shen and Michael Ferdman. The paper is available on IEEE Xplore.
This entry was posted on June 23, 2016.
New paper on streaming sorting networks published in ACM TODAES
A new overview paper that I co-authored with with Marcela Zuluaga and Markus Püschel of ETH Zurich has been published in ACM Transactions on Design Automation of Electronics Systems (TODAES). In this paper, we present new hardware structures for sorting that we call streaming sorting networks, which we derive through a mathematical formalism that we introduce, and an accompanying domain-specific hardware generator that translates our formal mathematical description into synthesizable RTL Verilog.
You can read the paper here, and see also our online sorting network generator, which allows you to use the tool described in this paper in your web browser.
As a preview, the following graph shows the cost of implementing various sorters with 16-bit fixed point input values that fit on a Xilinx Virtex-6 FPGA. The x-axis indicates the input size n, the y-axis indicates the number of FPGA configurable slices used, and the size of the marker quantifies the number of BRAMs used (BRAMs are blocks of on-chip memory available in FPGAs). The implementations using Batcher’s and Stone’s architectures can only sort up to 128 or 256 elements, respectively, on this FPGA. Conversely, our streaming sorting networks with streaming width w = 2 can sort up to 219 elements on this FPGA, and our smallest fully streaming design can sort up to 216 elements.
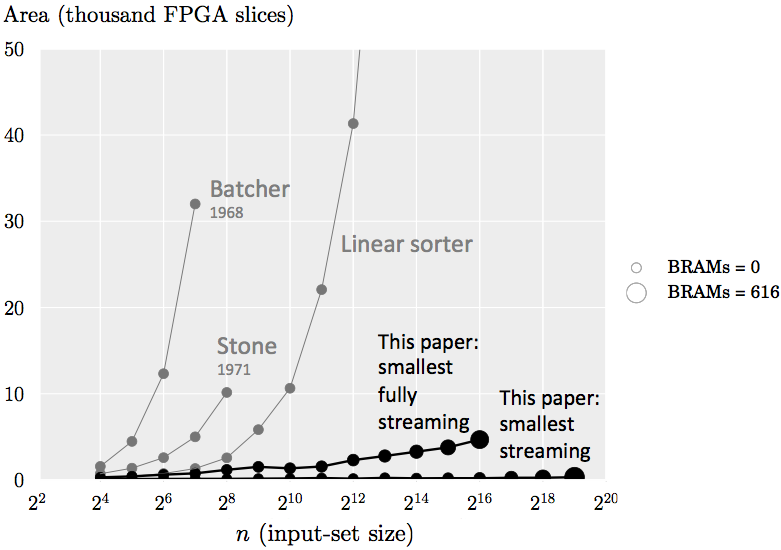
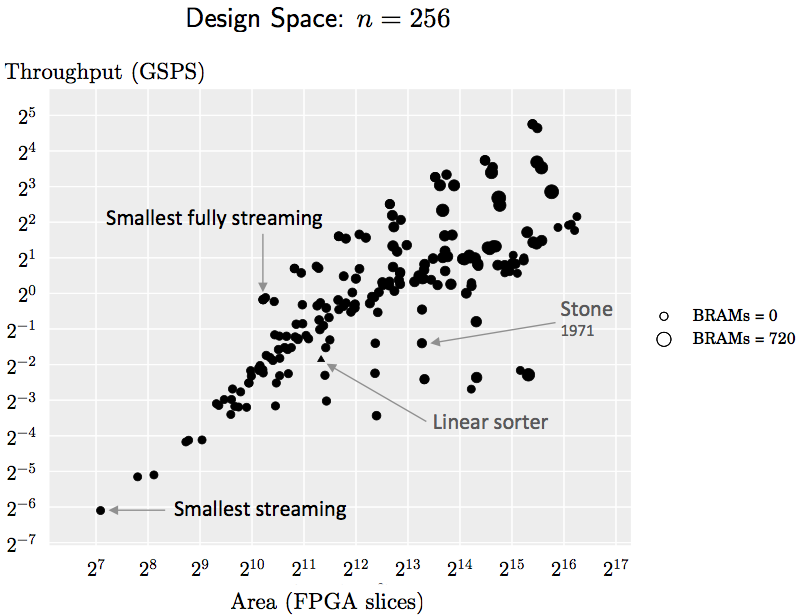
The following graph shows all 256-element sorting networks that we generate with our framework (using 16-bits per element) that fit onto the Virtex-6 FPGA. The x-axis indicates the number of configurable FPGA slices used, the y-axis indicates the maximum achievable throughput in giga samples per second, and the size of the marker indicates the number of BRAMs used. This plot shows that we can generate a wide range of design trade-offs that outperform previous implementations, such as that of Stone and the linear sorter (Batcher’s is omitted due to the high cost). For practical applications, only the Pareto-optimal ones (those toward the top left) would be considered.
This entry was posted on June 08, 2016.
NSF Funds work on Deep Learning with Clouds of FPGAs
The National Science Foundation program on Exploiting Parallelism and Scalability (XPS) has funded our project focused on using clouds of FPGAs for deep learning algorithms. This work is in collaboration with Mike Ferdman (Stony Brook CS) and Alex Berg (UNC Chapel Hill CS).
This entry was posted on August 15, 2015.
Announcing the MEMOCODE 2015 Design Contest
I am organizing the 2015 MEMOCODE Design Contest, which begins today and lasts through the month of June.
This year’s contest problem is will be the Continuous Skyline Computation. You can read the contest description here, and read more about MEMOCODE 2015 here.
This entry was posted on June 01, 2015.
New paper on IP Design Space Search to Appear at DAC 2015
A new paper in collaboration with Michael Papamichael and James C. Hoe of Carnegie Mellon is accepted for publication at the 2015 Design Automation Conference.
Michael Papamichael, Peter Milder, and James C. Hoe. “Nautilus: Fast Automated IP Design Space Search Using Guided Genetic Algorithms.”
This entry was posted on March 09, 2015.
NSF Funds work on Deep Learning with FPGAs
The National Science Foundation has provided new funding for my work on Deep Learning for Computer Vision with FGPAs (in collaboration with Michael Ferdman, Stony Brook CS, and Alex Berg, UNC Chapel Hill CS).
See also press coverage at Gigaom.
This entry was posted on August 08, 2014.
ACM TODAES Best Paper Award
My recent paper describing the Spiral Hardware Generation system has been awarded the 2014 ACM TODAES Best Paper Award.
This paper (co-written with Franz Franchetti, James C. Hoe, and Markus Püschel) presents an overview of my work on the Spiral hardware generation framework, a high-level synthesis and optimization engine that produces highly-customized hardware implementations of linear DSP transforms such as the FFT. This award was presented during the awards session at DAC 2014.
You can read the paper on the Spiral project site.
This entry was posted on June 09, 2014.
MEMOCODE 2014 Design Contest
I am please to announce the 2014 MEMOCODE Design Contest, which begins today and lasts through the month of June.
This year’s contest will be k-Nearest Neighbors with Mahalanobis distance metric. You can read the contest description here, and read more about MEMOCODE 14 here.
This entry was posted on June 01, 2014.
Teaching Fall 2014: ESE-305 and ESE-507
In the Fall 2014 semester I will be teaching two courses:
- ESE-305 (Deterministic Signals and Systems) on Tuesdays and Thursdays from 10:00–11:20am.
- ESE-507 (Advanced Digital System Design and Generation) on Mondays and Wednesdays from 4:00–5:20pm.
This entry was posted on March 31, 2014.
Execution signature compression paper to be presented next week at DATE 2014.
Jonah Caplan will soon present our work on execution signature compression at DATE 2014.
The talk will be in session “4.7 Dependable System Design” on Tuesday 3/25 at 6:00pm.
This entry was posted on March 21, 2014.
Work on symbol synchronization to be presented this week at OFC 2014
Robert Killey will be presenting our work on symbol synchronization for optical OFDM systems this week at the Optical Fiber Communication Conference.
The talk will be on Thursday 3/13 at 2:00pm in room 133, in the “Direct Detection” session.
This entry was posted on March 11, 2014.
New co-authored paper published in Optics Express
A new co-authored paper has been published in the Optics Express journal. The paper is on symbol synchronization for optical OFDM systems, and it is an extension of the work that will be presented in March at OFC.
You can read the paper at this link.
R. Bouziane, P. A. Milder, S. Erkılınç, L. Galdino, S. Kilmurray, B. C. Thomsen, P. Bayvel, and R. I. Killey. “Experimental demonstration of 30 Gb/s direct-detection optical OFDM transmission with blind symbol synchronisation using virtual subcarriers.” Optics Express, Vol. 22, Issue 4, pp. 4342–4348, 2014.
Abstract: The paper investigates the performance of a blind symbol synchronisation technique for optical OFDM systems based on virtual subcarriers. The test-bed includes a real-time 16-QAM OFDM transmitter operating at a net data rate of 30.65 Gb/s using a single OFDM band with a single FPGA-DAC subsystem and demonstrates transmission over 23.3 km SSMF with direct detection at a BER of 10−3. By comparing the performance of the proposed synchronisation scheme with that of the Schmidl and Cox algorithm, it was found that the two approaches achieve similar performance for large numbers of averaging symbols, but the performance of the proposed scheme degrades as the number of averaging symbols is reduced. The proposed technique has lower complexity and bandwidth overhead as it does not rely on training sequences. Consequently, it is suitable for implementation in high speed optical OFDM transceivers.
This entry was posted on February 19, 2014.
ESE-507 enrollment full (Spring 2014)
Unfortunately, ESE-507 for this semester is full. If you were not able to enroll, please note that I will be offering this course again in Fall 2014.
This entry was posted on January 27, 2014.
Paper to appear at Optical Fiber Communication Conference (OFC)
A recent co-authored paper on symbol synchronization for optical OFDM systems has been accepted at publication at the 2014 Optical Fiber Communication Conference (OFC).
Rachid Bouziane, Peter A. Milder, Sean Kilmurray, Benn C. Thomsen, Stephan Pachnicke, Polina Bayvel, and Robert I. Killey. “Blind symbol synchronisation in direct-detection optical OFDM using virtual subcarriers.”
Abstract: We investigate the performance of a novel blind symbol synchronisation technique using a 30.65Gb/s real-time 16-QAM OFDM transmitter with direct detection. The proposed scheme exhibits low complexity and does not have any bandwidth overhead.
This entry was posted on December 22, 2013.
Reliability paper to appear at DATE 2014
My recently coauthored paper on execution signature compression has been accepted to Design, Automation and Test in Europe (DATE) 2014.
Jonah Caplan, Maria Isabel Mera, Peter Milder, and Brett H. Meyer. “Trade-offs in Execution Signature Compression for Reliable Processor Systems.”
Abstract—As semiconductor processes scale, making transistors more vulnerable to transient upset, a wide variety of microarchitectural and system-level strategies are emerging to perform efficient error detection and correction computer systems. While these approaches often target various application domains and address error detection and correction at different granularities and with different overheads, an emerging trend is the use of state compression, e.g., cyclic redundancy check (CRC), to reduce the cost of redundancy checking. Prior work in the literature has shown that Fletcher’s checksum (FC), while less effective where error detection probability is concerned, is less computationally complex when implemented in software than the more-effective CRC. In this paper, we reexamine the suitability of CRC and FC as compression algorithms when implemented in hardware for embedded safety-critical systems. We have developed and evaluated parameterizable implementations of CRC and FC in FPGA, and we observe that what was true for software implementations does not hold in hardware: CRC is more efficient than FC across a wide variety of target input bandwidths and compression strengths.
This entry was posted on December 15, 2013.
Work on smart NICs funded by SRC
My collaborative research with Mike Ferdman (Stony Brook CS) on smart NICs has been funded by the Semiconductor Research Corporation (SRC).
This entry was posted on December 13, 2013.
New course, Spring 2014
My new course ESE-507, “Advanced Digital System Design and Generation” will be offered this Spring 2014 semester.
The field of digital system design has entered a new and complicated era. Digital designers now have increasingly large amounts of chip area to exploit, but they are strictly limited by the amount of power that can be consumed per transistor (the so-called “power wall”). Modern design practices must carefully balance a variety of system tradeoffs such as power, energy, area, throughput, latency, bandwidth, and reusability/customization of digital systems. This course will study how new design abstractions, languages, and tools can help address these problems from the system designer’s perspective.
This entry was posted on December 10, 2013.
Fall 2013: ESE 305
The fall semester has started. This semester I am teaching ESE-305 Deterministic Signals and Systems. Please note that the location of this course has changed to Javits room 103.
This entry was posted on August 25, 2013.
ESE-670 Final Projects
Yesterday in class, our students presented their final projects for ESE-670 Digital System Design and Generation. We saw some excellent projects on topics such as high-level synthesis and customized design generation tools. Congratulations to all the students for their hard work!
This entry was posted on May 09, 2013.
Optics Express paper
Our followup journal article, extending our ECOC 2012 paper has been published in Optics Express. You can read the article here.
“Real-time OFDM or Nyquist Pulse Generation — Which Performs Better with Limited Resources?” R. Schmogrow, R. Bouziane, M. Meyer, P. A. Milder, P. C. Schindler, R. I. Killey, P. Bayvel, C. Koos, W. Freude, and J. Leuthold. Optics Express, Vol. 20, Issue 26, pp. B543–B551. 2012.
This paper was chosen by the review committee as one of three highlights of the special issue on ECOC 2012.
Abstract: We investigate the performance and DSP resource requirements of digitally generated OFDM and sinc-shaped Nyquist pulses. The two multiplexing techniques are of interest as they offer highest spectral efficiency. The comparison aims at determining which technology performs better with limited processing capacities of state-of-the-art FPGAs. It is shown that a novel Nyquist pulse shaping technique, based on look-up tables requires lower resource count than equivalent IFFT-based OFDM signal generation while achieving similar performance with low inter- channel guard-bands in ultra-dense WDM. Our findings are based on a resource assessment of selected DSP implementations in terms of both simulations and experimental validations. The experiments were performed with real-time software-defined transmitters using a single or three optical carriers.
This entry was posted on December 14, 2012.
Paper at ECOC 2012
On Monday, Rene Schmogrow will be presenting a collaborative paper at the European Conference on Optical Communication (ECOC 2012). This work was performed as a collaboration with Rene Schmogrow, Matthias Meyer, Phillipp Schindler, Wolfgang Freude, and Juerg Leuthold at Karlsruhe Institute of Technology and with Rachid Bouziane, Polina Bayvel, and Robert Killey at University College London.
“Real-Time Digital Nyquist-WDM and OFDM Signal Generation: Spectral Efficiency versus DSP Complexity.” Rene Schmogrow, Rachid Bouziane, Matthias Meyer, Peter A. Milder, Philipp Schindler, Polina Bayvel, Robert Killey, Wolfgang Freude, and Juerg Leuthold.
Rene has been nominated for the Best Student Paper award for this work!
Abstract: We investigated the performance of Nyquist WDM and OFDM with respect to required DSP complexity. We demonstrate Nyquist pulse-shaping requiring less resources than IFFT-based OFDM for a similar performance. Tests are performed with QPSK/16QAM in a three-carrier WDM scenario.
Edit 9/20: Rene was one of two students awarded the Best Student Honorary Award for this work. Congratulations!
This entry was posted on September 15, 2012.
Optics Express article published
We have published a new collaborative paper on the real-time generation of 85.4 Gb/sec optical OFDM signals using FPGAs, with transmission over 400 km of standard single-mode fiber using a single polarization.
You can read the paper here.
“Generation and Transmission of 85.4 Gb/s Real-time 16QAM Coherent Optical OFDM Signals Over 400 km SSMR with Preamble-less Reception.” Rachid Bouziane, Rene Schmogrow, David Hillerkuss, Peter Milder, Christian Koos, Wolfgang Freude, Juerg Leuthold, Polina Bayvel, and Robert I. Killey. Optics Express, Vol. 20, Issue 19, pp. 21612–21617. 2012.
Abstract: This paper presents a real-time, coherent optical OFDM transmitter based on a field programmable gate array implementation. The transmitter uses 16QAM mapping and runs at 28 GSa/s achieving a data rate of 85.4 Gb/s on a single polarization. A cyclic prefix of 25% of the symbol duration is added enabling dispersion-tolerant transmission over up to 400 km of SSMF. This is the first transmission experiment performed with a real-time OFDM transmitter running at data rates higher than 40 Gb/s. A key aspect of the paper is the introduction of a novel method for OFDM symbol synchronization without relying on training symbols. Unlike conventional preamble-based synchronization methods which perform cross-correlations at regular time intervals and let the system run freely in between, the proposed method performs synchronization in a continuous manner ensuring correct symbol alignment at all times.
This entry was posted on September 05, 2012.
First day at Stony Brook
Today marks the first day of my first semester at Stony Brook. This semester I will be teaching ESE-305 Deterministic Signals and Systems.
This entry was posted on August 27, 2012.
Paper at LCTES 2012
This week, Marcela Zuluaga will present our paper on a machine-learning approach to predict Pareto-Optimal designs produced by high-level hardware generation tools such as Spiral at Languages, Compilers, Tools and Theory for Embedded Systems (LCTES 12). This work was performed with Marcela Zuluaga, Andreas Krause, and Markus Püschel at ETH Zurich.
“Smart” Design Space Sampling to Predict Pareto-Optimal Solutions. Marcela Zuluaga, Andreas Krause, Peter Milder, and Markus Püschel. LCTES 2012.
You can find the paper here. This paper has been nominated for the best paper award (3 papers nominated out of 18). You can read about prior work on generating sorting networks here, and prior work on generating linear transforms with Spiral here.
Abstract: Many high-level synthesis tools offer degrees of freedom in mapping high-level specifications to Register-Transfer Level descriptions. These choices do not affect the functional behavior but span a design space of different cost-performance tradeoffs. In this paper we present a novel machine learning-based approach that efficiently determines the Pareto-optimal designs while only sampling and synthesizing a fraction of the design space. The approach combines three key components: (1) A regression model based on Gaussian processes to predict area and throughput based on synthesis training data. (2) A “smart” sampling strategy, GP-PUCB, to iteratively refine the model by carefully selecting the next design to synthesize to maximize progress. (3) A stopping criterion based on assessing the accuracy of the model without access to complete synthesis data. We demonstrate the effectiveness of our approach using IP generators for discrete Fourier transforms and sorting networks. However, our algorithm is not specific to this application and can be applied to a wide range of Pareto front prediction problems.
This entry was posted on June 12, 2012.
Paper on generating sorting networks at DAC 2012
This week I will be traveling to the Design Automation Conference (DAC) in San Francisco, where Marcela Zuluaga will be presenting our collaborative work (with Markus Püschel) on generating sorting network hardware. You can find the paper here. The work described in this paper forms the basis for the Spiral Online Sorting Network IP Generator.
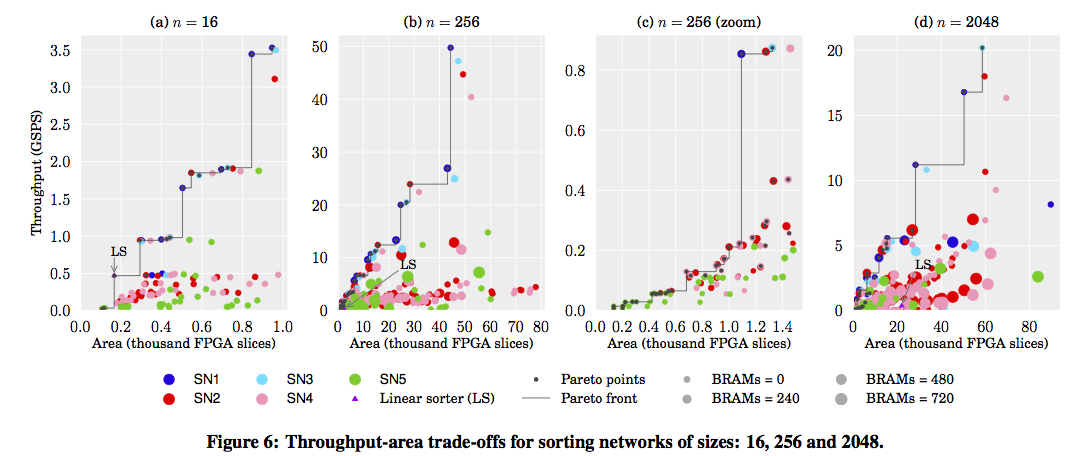
“Computer Generation of Streaming Sorting Networks.” Marcela Zuluaga, Peter Milder, and Markus Püschel. Design Automation Conference (DAC), 2012.
Abstract: Sorting networks offer great performance but become prohibitively expensive for large data sets. We present a domain-specific language and compiler to automatically generate hardware implementations of sorting networks with reduced area and optimized for latency or throughput. Our results show that the generator produces a wide range of Pareto-optimal solutions that both compete with and outperform prior sorting hardware.
This entry was posted on June 01, 2012.
FCCM 2012
Berkin Akin will be presenting our work on bandwidth-optimized large size 2D FFTs at the IEEE Symposium on Field-Programmable Custom Computing Machines (FCCM 2012) this week. This work was performed with Berkin Akin, Franz Franchetti, and James C. Hoe.
Memory Bandwidth Efficient Two-Dimensional Fast Fourier Transform Algorithm and Implementation for Large Problem Sizes. Berkin Akin, Peter Milder, Franz Franchetti, and James C. Hoe. FCCM 2012.
Abstract: Prevailing VLSI trends point to a growing gap between the scaling of on-chip processing throughput and off-chip memory bandwidth. An efficient use of memory bandwidth must become a first-class design consideration in order to fully utilize the processing capability of highly concurrent processing platforms like FPGAs. In this paper, we present key aspects of this challenge in developing FPGA-based implementations of two-dimensional fast Fourier transform (2D-FFT) where the large datasets must reside off-chip in DRAM. Our scalable implementations address the memory bandwidth bottleneck through both (1) algorithm design to enable efficient DRAM access patterns and (2) datapath design to extract the maximum compute throughput for a given level of memory bandwidth. We present results for double-precision 2D-FFT up to size 2,048-by-2,048. On an Altera DE4 platform our implementation of the 2,048-by-2,048 2D-FFT can achieve over 19.2 Gflop/s from the 12 GByte/s maximum DRAM bandwidth available. The results also show that our FPGA-based implementations of 2D-FFT are more efficient than 2D-FFT running on state-of- the-art CPUs and GPUs in terms of the bandwidth and power efficiency.
This entry was posted on April 27, 2012.
ACM TODAES article published
My article entitled Computer Generation of Hardware for Linear Digital Signal Processing Transforms has been published in ACM Transactions on Design Automation of Electronic Systems.
This paper (co-written with Franz Franchetti, James C. Hoe, and Markus Püschel) presents an overview of my work on the Spiral hardware generation framework, a high-level synthesis and optimization engine that produces highly-customized hardware implementations of linear DSP transforms such as the FFT.
A subset of this system’s functionality is used in my online FFT IP Core Generator, which allows you to create customized FFT cores directly from your web browser, and download the result as synthesizable RTL Verilog.
Abstract: Linear signal transforms such as the discrete Fourier transform (DFT) are very widely used in digital signal processing and other domains. Due to high performance or efficiency requirements, these transforms are often implemented in hardware. This implementation is challenging due to the large number of algorithmic options (e.g., fast Fourier transform algorithms or FFTs), the variety of ways that a fixed algorithm can be mapped to a sequential datapath, and the design of the components of this datapath. The best choices depend heavily on the resource budget and the performance goals of the target application. Thus, it is difficult for a designer to determine which set of options will best meet a given set of requirements.
In this article we introduce the Spiral hardware generation framework and system for linear transforms. The system takes a problem specification as input as well as directives that define characteristics of the desired datapath. Using a mathematical language to represent and explore transform algorithms and datapath characteristics, the system automatically generates an algorithm, maps it to a datapath, and outputs a synthesizable register transfer level Verilog description suitable for FPGA or ASIC implementation. The quality of the generated designs rivals the best available handwritten IP cores.
This entry was posted on April 05, 2012.
Poster presentation at ICASSP 2012
I’m attending ICASSP 2012 in Kyoto, Japan. Bob Koutsoyannis will be presenting our paper Improving Fixed-Piont Accuracy of FFT Cores in O-OFDM Systems on Thursday 3/29 in Poster Area D.
This entry was posted on March 28, 2012.
Poster presentation at FPGA 2012
FPGA 2012 is underway. Berkin Akin will be presenting a poster on our recent work on large-size 2D FFTs on FPGA (Poster Session 4, Friday at 3pm).
This entry was posted on February 22, 2012.