New paper on streaming sorting networks published in ACM TODAES
A new overview paper that I co-authored with with Marcela Zuluaga and Markus Püschel of ETH Zurich has been published in ACM Transactions on Design Automation of Electronics Systems (TODAES). In this paper, we present new hardware structures for sorting that we call streaming sorting networks, which we derive through a mathematical formalism that we introduce, and an accompanying domain-specific hardware generator that translates our formal mathematical description into synthesizable RTL Verilog.
You can read the paper here, and see also our online sorting network generator, which allows you to use the tool described in this paper in your web browser.
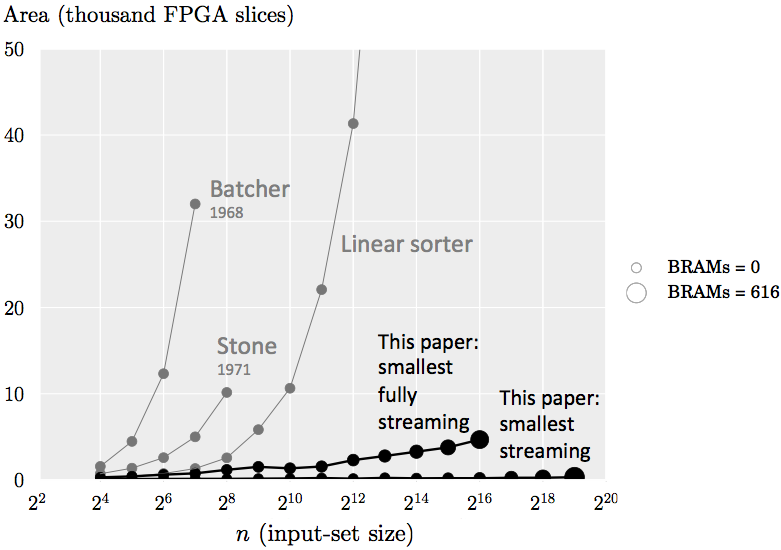
As a preview, the following graph shows the cost of implementing various sorters with 16-bit fixed point input values that fit on a Xilinx Virtex-6 FPGA. The x-axis indicates the input size n, the y-axis indicates the number of FPGA configurable slices used, and the size of the marker quantifies the number of BRAMs used (BRAMs are blocks of on-chip memory available in FPGAs). The implementations using Batcher’s and Stone’s architectures can only sort up to 128 or 256 elements, respectively, on this FPGA. Conversely, our streaming sorting networks with streaming width w = 2 can sort up to 219 elements on this FPGA, and our smallest fully streaming design can sort up to 216 elements.
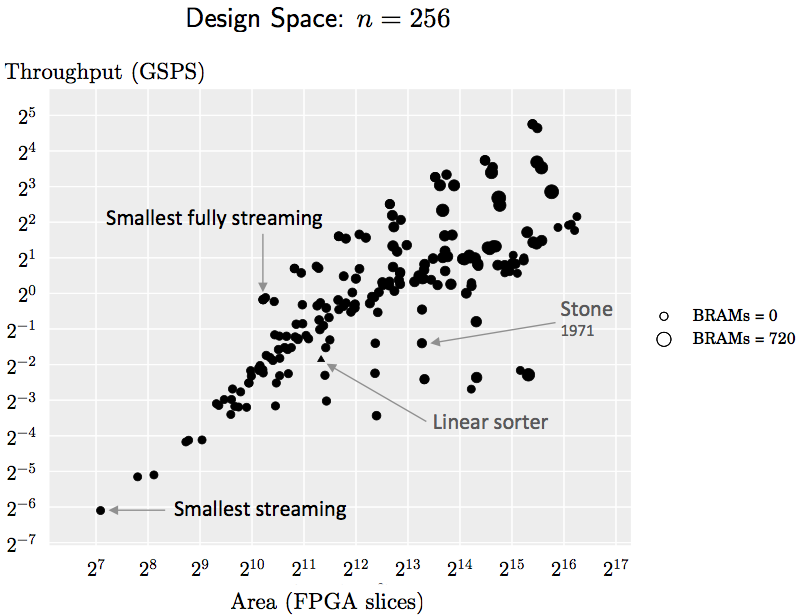
The following graph shows all 256-element sorting networks that we generate with our framework (using 16-bits per element) that fit onto the Virtex-6 FPGA. The x-axis indicates the number of configurable FPGA slices used, the y-axis indicates the maximum achievable throughput in giga samples per second, and the size of the marker indicates the number of BRAMs used. This plot shows that we can generate a wide range of design trade-offs that outperform previous implementations, such as that of Stone and the linear sorter (Batcher’s is omitted due to the high cost). For practical applications, only the Pareto-optimal ones (those toward the top left) would be considered.
This entry was posted on June 08, 2016.